








Now that everything and everyone have moved to the cloud, it’s a little bit difficult to distinguish capabilities between tools that can boost your performance as a data leader, analyst, scientist, or engineer!
In this overview, we will be highlighting one of Microsoft’s Azure tools, that is Azure Databricks, so you can determine what parts of the platform might make sense to add to your organization’s data stack.
Azure Dtatbricks is an Apache Spark-based analytics platform and was built on top of the one and only Microsoft Azure.
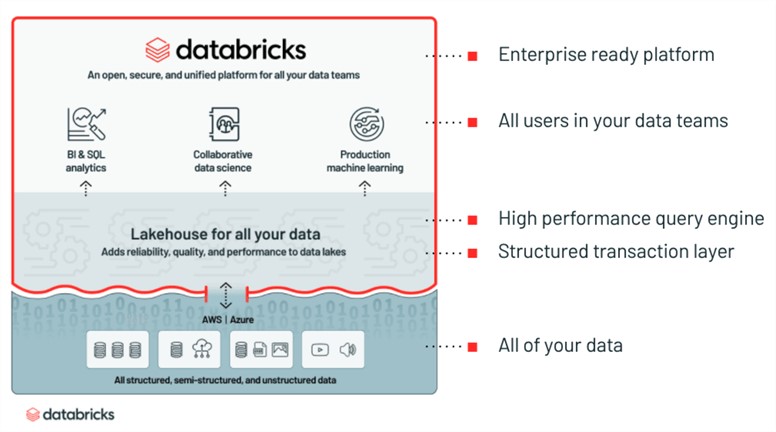
Azure Databricks is used mainly to process large workloads of data that allows collaboration between data scientists, data engineers, and business analysts to drive actionable insights with a one-click setup, streamlined workflows, and an interactive workspace.
There are four main reasons why you should consider Azure Databricks and why it’s a great analytics tool for big data workloads:
This is a notebook based environment that has the following features:
This is one of the main properties of Azure Databricks, and it takes the form of managed clusters.
Now, what’s a Cluster exactly? In simple words, it’s a group of virtual machines that divide up the work of a query in order to return results faster.
All you have to do is fill out 5-10 fields and then click a button! And now you can spin up a Spark cluster that is optimized beyond the open-source Spark, include many common data science and data analytical libraries, and auto-scale to meet the needs of the workloads.
Spark is the core here, and to put it into simple words, it’s an open-source distributed processing engine that processes data in memory, and that’s exactly what makes it a very popular asset for big data processing and machine learning.
Workloads and queries are executed by Spark on the Databricks platform.
This is an open-source file format that was specially built to deal with the limitations of traditional data lake file formats.
Delta is composed of Parquet, a columnar format optimized for big data workloads with added metadata and transaction tags.
How can you make use of it? Well, Delta offers the following key features that might be limitations in other file formats such as Parquet and ORC:
Read more: What Is Azure Data Lake?
This too is open source and we can define it by saying: it’s a machine learning framework that was built to manage ML lifecycle.
In data science, it can be very challenging to get machine learning into production! And ML Flow addresses the challenges with the following features:
In addition to those components, you’ll be able to use the additional benefits on the Databricks platform:
Designed to give SQL analysts a home within Databricks.
By switching views in the traditional Databricks workspace, the SQL Analytics Workspace gives an experience similar to the traditional SQL workbench.
As a user, with SQL analytics you can:
This feature is powered by SQL Endpoints, which are Spark clusters for SQL workloads.
If you’re working with Data Lake and you feel like it’s turning into a swamp and now you’re facing challenges around performance and reliability, then it might be beneficial to use Databricks to modernize your Data Lake.
If you’re a data scientist, then Databricks will help you get work from Development to Production into the hands of business users.
If you’re thinking about performance and how much it’s going to cost, then Databricks is the most cost-effective solution for you.
No need to build pipelines every time you want to access new data. You can open Data Lake to BI users through a tool like SQL Analytics within Databricks.
Curious about the solution?
Ctelecoms is a proud Microsoft partner in Saudi Arabia, working to deliver the best-in-class solutions to clients especially those interested in Azure.
Get in touch with our team for full support regarding deployment at: https://www.ctelecoms.com.sa/en/Form15/Contact-Us
Upgrade your IT to be as agile and efficient ...
